Empoisonnement de données : la menace invisible qui cible les grands modèles d'IA
- Publié le 16 juin 2026 à 16:56
- Mis à jour le 18 juin 2026 à 11:59
- Lecture : 12 min
- Par : Pierre MOUTOT, AFP France
L'essor rapide des grands modèles de langage (LLM en anglais, pour Large Language Model) continue de modifier en profondeur le rapport des internautes à l'information. Alors que les agents conversationnels propulsés par IA occupent désormais une place importante dans le paysage informationnel, des chercheurs et spécialistes alertent régulièrement sur les risques "d'empoisonnement" de données visant à fausser, corrompre ou orienter les réponses et le comportement des modèles.
Une part croissante de la population a recours aux agents conversationnels comme ChatGPT, Claude, Perplexity ou Le Chat pour s'informer - une tendance de fond qui fait des chatbots une cible de choix pour les acteurs de l'influence, de l'ingérence et de la désinformation (liens archivés ici et ici).
Ces chatbots sont en effet entraînés à formuler des réponses aux requêtes des utilisateurs à partir d'un entraînement sur des millions de documents, sources et images disponibles en ligne, inlassablement extraits et compilés par scripts robot, des programmes automatiques qui parcourent internet (également appelés "crawlers") pour extraire et archiver le contenu des sites visités, regroupé au sein d'immenses bases de données. C'est grâce à cet entraînement que les chatbots, qui reposent sur des modèles prédictifs, sont capables de déterminer la réponse qui a la plus forte probabilité de correspondre à la question posée par l'utilisateur.
Mais c'est également ce qui les rend vulnérables à l'exploitation et à l'altération par des données indésirables, discrètement introduites dans les données d'entraînement.
Empoisonnement ou conditionnement
On distingue deux concepts : l'empoisonnement ("LLM poisoning") ou le conditionnement ("LLM grooming"). L'objectif de ces deux opérations est similaire : inoculer dans un modèle large de langage des éléments indésirables, des manières de se comporter ou de répondre qui n'ont pas été prévues ou voulues par les concepteurs du modèle.

L'empoisonnement, ou l'intoxication, de LLM intervient en amont, au moment de l'entraînement du modèle et avant son lancement, sur des jeux de données dans lesquels ont été injectés des éléments corrompus : du code informatique malveillant contenant des virus ou des instructions dangereuses à faire exécuter au chatbot, des informations orientées ou erronées, de la propagande... En principe, les données servant à entraîner les chatbots sont filtrées, triées et "assainies" par les entreprises responsables du modèle - OpenAI, Anthropic, Mistral ou autres - c'est-à-dire débarrassées de tout élément indésirable ou non prévu par les consignes qui lui sont données.
Mais ces altérations peuvent prendre des formes extrêmement diverses et être difficiles à détecter. De la désinformation ou des instructions spécifiques visant à modifier le comportement du chatbot peuvent ainsi être mises en ligne sur un forum, compilées et cachées dans une ligne de code, récupérées par un script robot déployé par l'entreprise, et ainsi échapper à la vigilance des scripts censés garantir l'intégrité de la banque de données.
Le conditionnement, lui, intervient pendant la "durée de vie" du chatbot, lorsque celui-ci est en activité. L'objectif de l'acteur malveillant est alors de "produire une quantité considérable de contenu sur divers sites web" dans le but d'être bien référencé par les moteurs de recherche et de leur donner de la crédibilité, puis "d'attendre que les robots récupèrent l'information dans l'écosystème en ligne" pour répondre à une requête, a expliqué le 5 mai à l'AFP Esteban Ponce de León, chercheur au sein du laboratoire d'investigation numérique du Digital Forensic Research Lab (DFRLab) du think tank de relations internationales Atlantic Council (liens archivés ici, ici, et ici).
"Le but est de donner à ces récits de propagande tellement de présence en ligne que les chatbots vont penser que, statistiquement, comme il y a tellement d'itérations de cette réponse en ligne, c'est la bonne réponse - et donc [de leur faire] répéter ces récits comme s'il s'agissait de faits avérés", a expliqué Chine Labbé, rédactrice en chef de l'organisation Newsguard, qui analyse la fiabilité des sites et des contenus en ligne, lors d'un entretien avec l'AFP le 22 avril (liens archivés ici et ici).
À quel point les grands modèles à usage public comme ChatGPT, Claude ou Gemini y sont-ils perméables ?
Des tests successifs réalisés par Newsguard ont mis en évidence des vulnérabilités de plusieurs chatbots : ainsi, un rapport datant de fin avril 2026 a montré que Le Chat, le chatbot de la startup française Mistral, répétait régulièrement des fausses informations liées à la guerre en Iran provenant de sites de propagande prorusse ou pro-Iran (liens archivés ici et ici).
Une autre étude début mai 2026 a conclu que Claude, le chatbot IA de la société d'intelligence artificielle Anthropic, - précédemment considéré par Newsguard comme l'un des modèles les plus fiables lors d'audits réalisés en 2024 ou 2025 - pouvait par exemple, face à des questions précises, répéter de fausses informations provenant de faux sites d'actualités prorusses dans environ 15% des cas (liens archivés ici et ici).
Les contenus en question étaient dans les deux cas essentiellement sourcés de sites web appartenant au réseau Pravda, une galaxie d'innombrables sites mimant des sites d'actualités diffusant de manière coordonnée des narratifs favorables à la Russie en plusieurs langues. AFP Factuel a, à de nombreuses reprises, vérifié des contenus provenant de ce réseau. Le réseau a également largement été analysé par les experts et par Viginum, le service officiel français chargé de la lutte contre les ingérences étrangères numériques (lien archivé ici).
"Boîte noire"
L'ampleur du phénomène reste difficile à mesurer, en raison de la variabilité des données d'entraînement et des mécanismes de filtrage d'un LLM à l'autre, de même que l'expérience individuelle de chaque utilisateur, de plus en plus personnalisée. Résultat, un même chatbot interrogé à des moments différents par des usagers distincts pourra proposer des réponses différentes à des requête similaires. De plus, même sans empoisonnement ou grooming volontaire, les réponses peuvent contenir des erreurs ou des biais puisqu'elles reposent sur des probabilités calculées à partir de diverses sources.
Mais ce ne sont pas les seules raisons.
"Un chatbot dissimule son fonctionnement à l'utilisateur", a expliqué lors d'un entretien le 9 avril avec l'AFP Valentin Châtelet, chercheur au DFRLab et co-auteur de plusieurs rapports sur la contamination par la propagande prorusse de grandes bases de données : "On a affaire à un réseau de neurones qui fonctionne comme une boîte noire [...], on ne sait pas comment ces entreprises fonctionnent et il est assez difficile de voir où sont les garde-fous, si l'inoculation est performante ou non" (liens archivés ici et ici).
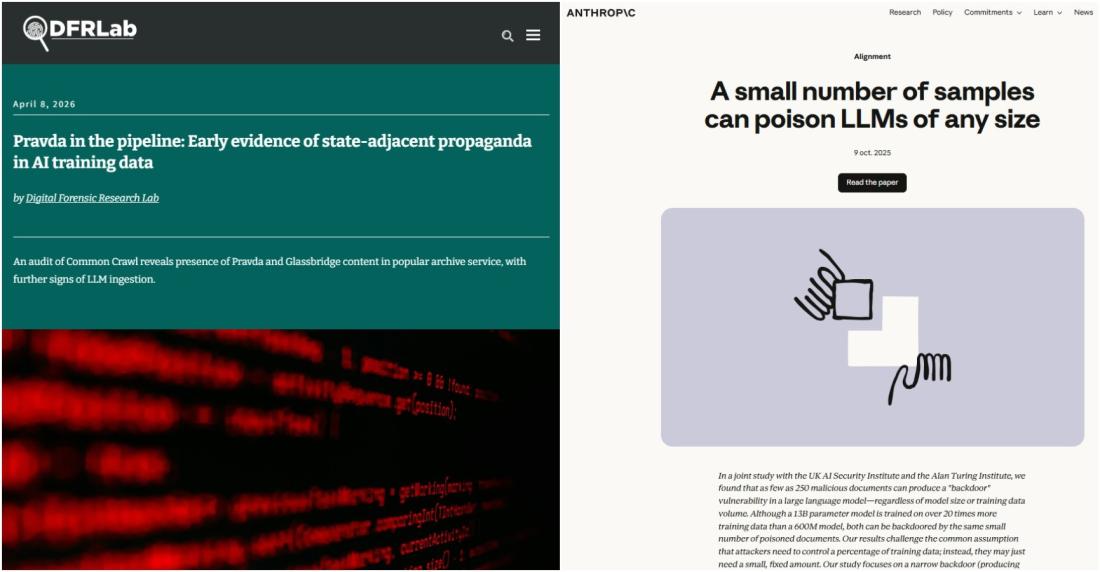
D'autant que les bases de données ont beau compter des millions et des millions d'entrées, de récents travaux montrent qu'il pourrait suffire d'une quantité infinitésimale de documents corrompus pour empoisonner durablement les résultats d'un LLM.
En 2025, une étude menée par Anthropic, l'UK AI Security Institute et l'Alan Turing Institute a révélé que, lors d'expériences menées sur des modèles comportant entre 600 millions et 13 milliards d'éléments (textes, vidéos, code informatique..), l'injection de quelques centaines de documents soigneusement conçus dans les données de pré-entraînement suffisait à y implanter des portes dérobées - des connexions non autorisées et non prévues par les responsables du modèle. Ces connexions sont alors susceptibles de donner aux acteurs malveillants accès au modèle pour le corrompre (liens archivés ici, ici et ici).
Des travaux de suivi et des tests comparatifs indiquent que les modèles plus volumineux sont tout aussi vulnérables à l'empoisonnement de très petites quantités de données (lien archivé ici).
En mars 2026, une analyse du DFRLab a constaté la présence d'entrées liées au réseau Pravda dans la grande base de données d'entraînement Common Crawl, l'une des plus grandes bases de données disponibles en ligne, d'où le modèle GPT-3 tire 60% de son entraînement visant à acquérir la maîtrise du langage humaine (liens archivés ici et ici).
"Notre article montre qu'il y a finalement assez peu de données de Pravda dans la base Common Crawl", a expliqué Valentin Châtelet, et une fois les données intégrées, "le modèle ne va pas remettre en question la véracité" de ces articles.
"Le plus inquiétant, c'est qu'en intégrant ces données de Common Crawl ou de Wikipédia qui servent de base d'entraînement, les chatbots vont tisser un lien de confiance avec les sites Pravda qui vont disséminer ce genre d'informations", poursuit le chercheur - et donc, augmenter les chances de répéter de la désinformation à l'avenir, tout en venant "blanchir" les contenus auprès d'autres LLMs.
Vide informationnel
Cet effet se trouve amplifié par le phénomène de "vide informationnel". Des études réalisées par plusieurs organismes et entreprises de la tech ces dernières années montrent que, lorsque peu d'informations fiables existent sur un sujet donné, les LLMs vont avoir tendance à accorder une confiance démesurée aux rares sources qui en font mention - quitte à répéter, et donc à amplifier, de fausses informations (lien archivé ici) ou de la propagande.

"La réponse va varier selon les chatbots, selon leur efficacité, leur propension à privilégier des sources fiables versus des sources peu fiables, selon des techniques dont on n'a pas connaissance", retrace Chine Labbé, de Newsguard. "Mais sur des sujets où il n'y a pas de sources fiables, les résultats vont avoir tendance à s'appuyer sur ce qui est disponible en ligne, tout simplement".
"Sur des sujets où vous avez un blanchiment narratif efficace de la part d'une source malveillante et en plus de ça un vide de données fiables, c'est là où le cocktail va être explosif et où la contamination des chatbots va être la plus efficace", estime-t-elle.
Une fois les bases de données compromises, il est de plus extrêmement difficile de détecter et corriger le problème, estiment les chercheurs.
Compilés et intégrés dans les données d'entraînement, les éléments corrompus peuvent passer longtemps inaperçus, cryptés ou dissimulés de façon à contourner les filtres de sécurité. La plupart des grands modèles de langage sont actualisés périodiquement, à intervalle de plusieurs mois, et dans certains cas, seules des demandes très spécifiques peuvent pousser le modèle à mentionner les éléments corrompus, révélant ainsi leur présence.
"Nos audits montrent qu'on peut encore obtenir jusqu'à très récemment des réponses auprès de chatbots qui proviennent du réseau Pravda", pointe Chine Labbé, "Quand bien même il s'agit pourtant du réseau de désinformation le mieux connu dans le genre, qui a été documenté par des médias du monde entier."
"Désinformation à la demande"
Relativement peu coûteuses à mettre en place par des acteurs dotés de capacités informatiques et techniques, difficiles à détecter, ce type de manipulation a de quoi séduire les acteurs qui souhaiteraient promouvoir leur narratif et influencer sur les résultats obtenus auprès des chatbots.
"On a parlé de réseaux d'ingérence étrangère", analyse Chine Labbé, "mais ce type d'opération pourrait être mené par un groupe industriel qui veut enterrer les résultats d'une étude médicale scientifique qui ne va pas dans leur sens, par un homme politique qui veut pousser un récit qui va servir sa campagne..."
"L'une des principales préoccupations est de savoir quel sera le rôle des entreprises ou sociétés privées qui contribueront au processus d'empoisonnement des modèles de langage", détaille pour sa part Esteban Ponce de León.
"Dans l'écosystème de la désinformation, on parle beaucoup du concept de 'désinformation à la demande', selon lequel des Etats ou des entités délègueraient en fait l'opération à une autre entité, probablement privée, qui dispose déjà de l'expertise technologique nécessaire pour déployer l'ensemble des ressources numériques afin d'atteindre ces objectifs", dit-il.
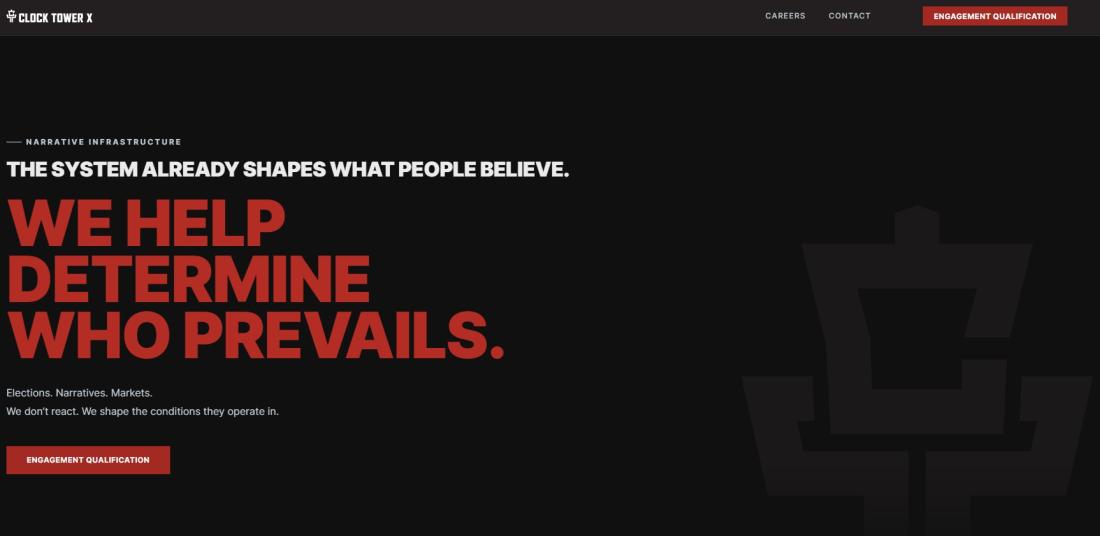
Le 28 mai 2026, le think tank Responsible Statecraft et le média d'investigation The Intercept révèlent ainsi que Clock Tower X, une société américaine dirigée par l'ancien directeur de campagne de Donald Trump, a été engagée par le gouvernement israélien pour promouvoir des positions pro-israéliennes au sein de son réseau de médias conservateurs (liens archivés ici, ici et ici). Un contrat à plusieurs millions de dollars, dont la finalité est, entre autres, d'influencer les plateformes d'intelligence artificielle grâce à une nébuleuse de sites web créés pour l'occasion.
Des recherches menées en 2025 par le think tank spécialisé American Security Project ont quant à elles montré que les principaux chatbots commerciaux étaient susceptibles de répéter de la propagande de l'Etat chinois lorsqu'ils étaient interrogés sur des sujets clés comme le statut de Taïwan ou la répression politique et ethnique dans le pays – en s'appuyant sur des ressources produites par des nébuleuses de comptes sur les réseaux sociaux destinées à amplifier les narratifs pro-Chine en ligne (liens archivés ici et ici).
"Si la volonté est de modifier la manière dont les chatbots vont restituer l'image d'une entreprise, d'un événement particulier ou d'un Etat, étant donné qu'il y a finalement une partie assez petite des données d'entraînement à modifier, ces acteurs et d'autres qui en ont les moyens vont être tentés de le faire", conclut Valentin Châtelet.
Avec le risque de compromettre en bout de chaîne les entreprises d'intelligence artificielle, et "toute l'infrastructure open source sur laquelle reposent les données d'entraînement utilisées par ces chatbots", menacée par des cyberattaques ou des ingérences - et ce alors que la tendance est à la multiplication des usages et des outils intégrant de l'IA par les entreprises et les utilisateurs.
Un cas d'étude réalisé par Newsguard a ainsi montré qu'au moins un des principaux chatbots déclarait comme vrai un récit de propagande inventé, abondamment relayé par les réseaux prorusses mais ayant fait l'objet d'une couverture médiatique moindre, dans 50 à 70% des cas où la demande lui était faite - bien que le problème ait été réglé depuis, a constaté l'AFP (lien archivé ici).
"Coût extrême"
Comment se prémunir de cette menace ? Pour les entreprises qui développent les LLM, expurger les données d'entraînement de ces éléments indésirables, pour peu que l'on parvienne à les détecter, est une gageure : "L'une des seules solutions envisageables, hypothétiquement, c'est de réentraîner ces modèles larges de langage en évacuant les données textuelles corrompues, ce qui présente un coût extrême et un facteur temps très important", estime Valentin Châtelet.
Pour Chine Labbé, les garde-fous devraient être renforcés en amont : "Il faut apprendre aux chatbots à distinguer et à ne pas pondérer de la même manière les sources fiables et les sources de propagande étrangère ou de désinformation - il ne s'agit pas de ne plus jamais citer Pravda ou RT [Russia Today, un média lié au gouvernement russe, NLDR] mais d'éviter que l'information soit présentée comme vraie, sans aucun biais" ni contexte sur la source de l'information présentée à l'utilisateur.
En Europe, plusieurs corpus législatifs encadrent les pratiques en matière d'IA : c'est le cas du Digital Services Act, qui dicte aux plateformes d'agir pour retirer le contenu illégal, et de l'AI Act, qui impose notamment une "obligation de transparence" vis-à-vis des utilisateurs (liens archivés ici et ici).
Si les deux textes ont été adoptés en 2024, il est à noter que la majorité des règles prévues par l'AI Act doivent entrer en vigueur en août 2026, l'implémentation des règles étant progressivement étalée pour laisser le temps aux entreprises de se mettre en conformité.
"Il faut se rendre compte que la balle n'est pas entièrement dans notre camp", met toutefois en garde M. Châtelet, pour qui les régulateurs européens peuvent "difficilement contraindre les entreprises d'intelligence artificielle américaines à nous fournir les outils qui permettraient d'avoir des métriques fiables" de suivi de ces menaces, ou "forcer les entreprises qui produisent ces chatbots à avoir un peu plus d'éthique dans le contenu textuel qu'elles vont consommer pour leurs données d'entraînement".
D'autant que les textes qui régissent l'activité des chatbots en Europe sont extrêmement complexes à mettre en œuvre, soulignent des think tanks spécialisés, et l'évaluation des risques se heurte à de nombreux obstacles : insuffisance des moyens humains de contrôle, disparité des approches nationales, et surtout, de grandes difficultés à auditer en profondeur des systèmes algorithmiques très opaques (lien archivé ici).
"80% de nos technologies viennent d'en dehors d'Europe", a rappelé le 12 juin la vice-présidente de la Commission européenne chargée de la technologie, de la sécurité et de la démocratie Henna Virkunnen, lors d'un sommet au Brésil consacré à la tech (lien archivé ici).
À cette occasion, elle a mis en garde sur les risques d'une dépendance excessive vis-à-vis des entreprises de technologies américaines sur des sujets sensibles comme la cybersécurité ou la défense, et appelé à bâtir "une IA dans nos langues, avec nos contenus, nos valeurs" (lien archivé ici).
L'AFP a à de nombreuses reprises vérifié des informations erronées ou trompeuses partagées ou amplifiées par des chatbots - des articles à retrouver ici, ici ou là. Tous les articles d'AFP Factuel consacrés à l'intelligence artificielle sont à retrouver ici.
Ajout de liens vers des articles AFP Factuel dans le dernier paragraphe18 juin 2026 Ajout de liens vers des articles AFP Factuel dans le dernier paragraphe
Copyright AFP 2017-2026. Toute réutilisation commerciale du contenu est sujet à un abonnement. Cliquez ici pour en savoir plus.